Order Independent Transparency (OIT) with Compute
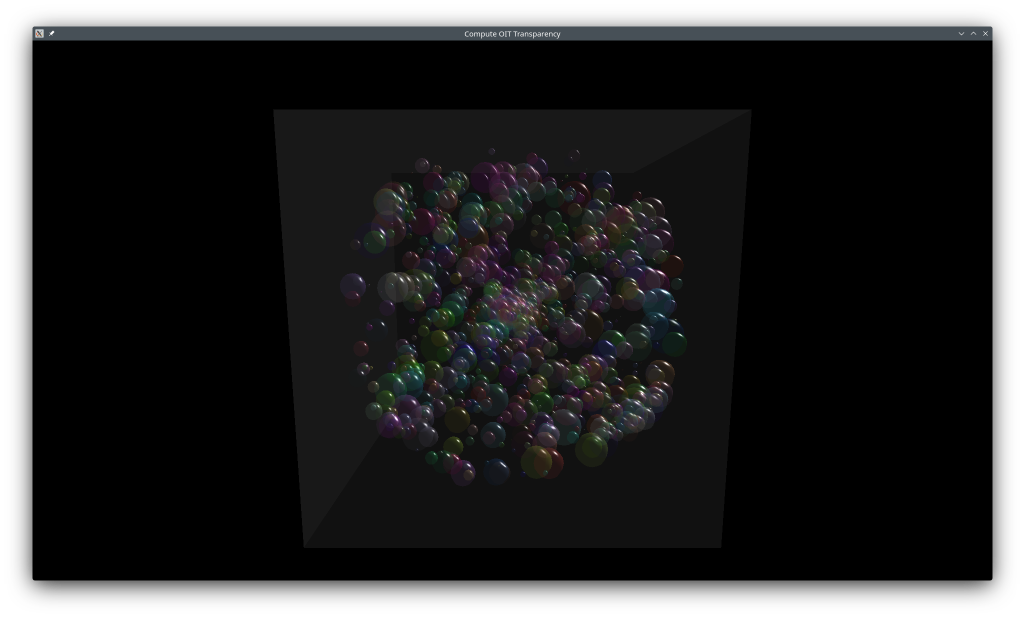
This example solves the transparency rendering problem where traditional alpha blending requires sorting objects back-to-front. Order-independent transparency (OIT) allows rendering transparent objects in any order by storing all fragments per-pixel in a linked list, then sorting and blending them in a final pass. This technique combines fragment shaders to build linked lists, storage buffers for fragment data, and compute shaders for particle updates.
The example uses the KDGpuExample helper API for simplified setup.
Key technique: Per-pixel linked list with atomic operations for lock-free fragment insertion, followed by in-shader sorting and blending.
Use cases: Complex transparent scenes (particles, glass), effects, volumetric rendering, avoiding CPU sort overhead.
The Approach
This example uses a per-pixel linked list:
- Particle Update: A compute shader updates particle positions each frame.
- Clear: The linked list buffer and the "head pointer" image is cleared to prepare for the new frame.
- Fragment Storage: Transparent objects are rendered. Their fragment shader uses atomic operations to insert fragment data (color, depth, next pointer) into a global linked list storage buffer and updates a 2D image storing the head-node index for each pixel.
- Compositing: A full-screen pass reads the linked list for each pixel, sorts the fragments by depth, and blends them front-to-back into the final image.
Data Structures
Each particle carries position, velocity, and color. The RGBA color's alpha channel controls transparency for all spheres.
| struct ParticleData {
glm::vec4 positionAndRadius;
glm::vec4 velocity;
glm::vec4 color;
};
static_assert(sizeof(ParticleData) == 12 * sizeof(float));
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
Each fragment stored in the linked list contains its color, depth, and the index of the next node. The buffer is sized dynamically as described in [Alpha Pass (Linked List Generation)].
| struct FragmentInfo {
glm::vec4 color;
float depth;
int32_t next;
float _pad[2];
};
static_assert(sizeof(FragmentInfo) == 8 * sizeof(float));
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
Initialization
The example initializes several nested structures to manage the different passes: m_particles, m_alpha, m_compositing, m_cubeMesh, m_sphereMesh, and m_global.
Particle Simulation
A compute shader updates particle positions every frame. The storage buffer binding layout uses a single SSBO bound at stage ComputeBit. A specialization constant is used to bake the local workgroup X size (256) into the shader at pipeline-creation time, matching the dispatch calculation ParticlesCount / 256:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46 | auto initializeComputePipeline = [this]() -> void {
// Create a compute shader (spir-v only for now)
auto computeShaderPath = KDGpuExample::assetDir().file("shaders/examples/compute_oit_transparency/particles.comp.spv");
auto computeShader = m_device.createShaderModule(KDGpuExample::readShaderFile(computeShaderPath));
// Create bind group layout consisting of a single binding holding a SSBO
m_particles.bindGroupLayout = m_device.createBindGroupLayout(BindGroupLayoutOptions{
.bindings = {
{
.binding = 0,
.resourceType = ResourceBindingType::StorageBuffer,
.shaderStages = ShaderStageFlags(ShaderStageFlagBits::ComputeBit),
},
},
});
// Create a pipeline layout (array of bind group layouts)
m_particles.computePipelineLayout = m_device.createPipelineLayout(PipelineLayoutOptions{
.bindGroupLayouts = { m_particles.bindGroupLayout } });
// Create a bindGroup to hold the UBO with the transform
m_particles.particleBindGroup = m_device.createBindGroup(BindGroupOptions{
.layout = m_particles.bindGroupLayout,
.resources = {
{
.binding = 0,
.resource = StorageBufferBinding{ .buffer = m_particles.particleDataBuffer },
},
},
});
m_particles.computePipeline = m_device.createComputePipeline(ComputePipelineOptions{
.layout = m_particles.computePipelineLayout,
.shaderStage = {
.shaderModule = computeShader,
// Use a specialization constant to set the local X workgroup size
.specializationConstants = {
{
.constantId = 0,
.value = 256,
},
},
},
});
};
initializeComputePipeline();
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
Each frame, the compute pass dispatches enough workgroups to cover all particles:
| // Particles
{
auto computePass = commandRecorder.beginComputePass();
computePass.setPipeline(m_particles.computePipeline);
computePass.setBindGroup(0, m_particles.particleBindGroup);
constexpr size_t LocalWorkGroupXSize = 256;
computePass.dispatchCompute(ComputeCommand{ .workGroupX = ParticlesCount / LocalWorkGroupXSize });
computePass.end();
}
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
Alpha Pass (Linked List Generation)
The alpha pass bind group layout exposes two fragment-stage bindings: a StorageBuffer for the per-pixel linked list nodes, and a StorageImage (R32_UINT) for the head-pointer texture:
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | m_alpha.alphaBindGroupLayout = m_device.createBindGroupLayout(BindGroupLayoutOptions{
.bindings = {
{
.binding = 0,
.resourceType = ResourceBindingType::StorageBuffer,
.shaderStages = ShaderStageFlags(KDGpu::ShaderStageFlagBits::FragmentBit),
},
{
.binding = 1,
.resourceType = ResourceBindingType::StorageImage,
.shaderStages = ShaderStageFlags(KDGpu::ShaderStageFlagBits::FragmentBit),
},
},
});
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
On the shader side, those same two bindings are declared as a coherent SSBO (with an atomic counter in the first field) and a coherent uimage2D:
| layout(std430, set = 0, binding = 0) coherent buffer AlphaFragments
{
uint nextIdx;
vec3 _pad;
AlphaFragment fragments[];
}
alphaFragments;
layout(set = 0, binding = 1, r32ui) uniform coherent uimage2D alphaHeadPointer;
|
Filename: compute_oit_transparency/alpha.frag
Both resources are sized to the window dimensions and (re)created on every resize. Up to 8 transparent fragments are budgeted per pixel; the buffer is padded by one vec4 to store the global atomic counter at offset 0:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 | // Recreated fragmentHeadsPointer texture
m_alpha.fragmentHeadsPointer = m_device.createTexture(KDGpu::TextureOptions{
.label = "fragmentHeadPointers",
.type = KDGpu::TextureType::TextureType2D,
.format = KDGpu::Format::R32_UINT,
.extent = { std::max(m_window->width(), uint32_t(1)), std::max(m_window->height(), uint32_t(1)), 1 },
.mipLevels = 1,
.usage =
KDGpu::TextureUsageFlagBits::TransferDstBit | KDGpu::TextureUsageFlagBits::StorageBit,
.memoryUsage = KDGpu::MemoryUsage::GpuOnly,
});
m_alpha.fragmentHeadsPointerView = m_alpha.fragmentHeadsPointer.createView(KDGpu::TextureViewOptions{
.label = "fragmentHeadPointersView",
.range = {
.aspectMask = KDGpu::TextureAspectFlagBits::ColorBit,
.levelCount = 1,
},
});
m_alpha.fragmentHeadsPointerLayout = TextureLayout::Undefined;
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
1
2
3
4
5
6
7
8
9
10
11
12 | // Recreate fragmentsLinkedList SSBO
const size_t MaxFragmentCount = std::max(m_window->width(), uint32_t(1)) * std::max(m_window->height(), uint32_t(1)) * 8;
// vec4 to hold nextId + array of structs
m_alpha.fragmentLinkedListBufferByteSize = sizeof(float) * 4 + MaxFragmentCount * sizeof(FragmentInfo);
m_alpha.fragmentLinkedListBuffer = m_device.createBuffer(KDGpu::BufferOptions{
.label = "FragmentSSBO",
.size = m_alpha.fragmentLinkedListBufferByteSize,
.usage = KDGpu::BufferUsageFlagBits::StorageBufferBit |
KDGpu::BufferUsageFlagBits::TransferDstBit,
.memoryUsage = KDGpu::MemoryUsage::GpuOnly,
});
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
In the alpha pass itself, the storage buffer and head pointer image are cleared, layout transitions and memory barriers are inserted to guarantee write visibility, and then the sphere and cube meshes are drawn using instanced rendering:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95 | // Alpha
{
// Wait for SSBO writes completion by ComputeShader
commandRecorder.bufferMemoryBarrier(KDGpu::BufferMemoryBarrierOptions{
.srcStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::ComputeShaderBit),
.srcMask = KDGpu::AccessFlagBit::ShaderWriteBit,
.dstStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::VertexInputBit),
.dstMask = KDGpu::AccessFlagBit::VertexAttributeReadBit,
.buffer = m_particles.particleDataBuffer,
});
// Clear Fragment List SSBO
commandRecorder.clearBuffer(KDGpu::BufferClear{
.dstBuffer = m_alpha.fragmentLinkedListBuffer,
.byteSize = m_alpha.fragmentLinkedListBufferByteSize,
});
// Transition fragmentHeadsPointer to general layout if needed
if (m_alpha.fragmentHeadsPointerLayout == KDGpu::TextureLayout::Undefined) {
commandRecorder.textureMemoryBarrier(KDGpu::TextureMemoryBarrierOptions{
.srcStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::TopOfPipeBit),
.srcMask = KDGpu::AccessFlagBit::None,
.dstStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::TransferBit),
.dstMask =
KDGpu::AccessFlagBit::TransferWriteBit | KDGpu::AccessFlagBit::TransferReadBit,
.oldLayout = KDGpu::TextureLayout::Undefined,
.newLayout = KDGpu::TextureLayout::General,
.texture = m_alpha.fragmentHeadsPointer,
.range = {
.aspectMask = KDGpu::TextureAspectFlagBits::ColorBit,
.levelCount = 1,
},
});
m_alpha.fragmentHeadsPointerLayout = KDGpu::TextureLayout::General;
}
// Clear Fragment Head Texture Image
commandRecorder.clearColorTexture(KDGpu::ClearColorTexture{
.texture = m_alpha.fragmentHeadsPointer,
.layout = KDGpu::TextureLayout::General,
.clearValue = {
.uint32 = { 0, 0, 0, 0 },
},
.ranges = {
{
.aspectMask = KDGpu::TextureAspectFlagBits::ColorBit,
.levelCount = 1,
},
},
});
// Wait until fragments SSBO has been cleared
commandRecorder.bufferMemoryBarrier(KDGpu::BufferMemoryBarrierOptions{
.srcStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::TransferBit),
.srcMask = KDGpu::AccessFlagBit::TransferWriteBit,
.dstStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::FragmentShaderBit),
.dstMask = KDGpu::AccessFlagBit::ShaderWriteBit | KDGpu::AccessFlagBit::ShaderReadBit,
.buffer = m_alpha.fragmentLinkedListBuffer,
});
// Wait until fragments SSBO Heads pointer image has been cleared
commandRecorder.textureMemoryBarrier(KDGpu::TextureMemoryBarrierOptions{
.srcStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::TransferBit),
.srcMask = KDGpu::AccessFlagBit::TransferWriteBit,
.dstStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::FragmentShaderBit),
.dstMask = KDGpu::AccessFlagBit::ShaderWriteBit | KDGpu::AccessFlagBit::ShaderReadBit,
.oldLayout = KDGpu::TextureLayout::General,
.newLayout = KDGpu::TextureLayout::General,
.texture = m_alpha.fragmentHeadsPointer,
.range = {
.aspectMask = KDGpu::TextureAspectFlagBits::ColorBit,
.levelCount = 1,
},
});
// Render Alpha meshes to fragment list
auto alphaPass = commandRecorder.beginRenderPass(*m_alpha.renderPassOptions);
// Draw Spheres
alphaPass.setPipeline(m_sphereMesh.graphicsPipeline);
alphaPass.setBindGroup(0, m_alpha.alphaLinkedListBindGroup);
alphaPass.setBindGroup(1, m_global.cameraBindGroup);
alphaPass.setVertexBuffer(0, m_sphereMesh.vertexBuffer);
alphaPass.setVertexBuffer(1, m_particles.particleDataBuffer); // Per instance Data
alphaPass.draw(DrawCommand{ .vertexCount = uint32_t(m_sphereMesh.vertexCount), .instanceCount = ParticlesCount });
// Draw Cube
alphaPass.setPipeline(m_cubeMesh.graphicsPipeline);
alphaPass.setBindGroup(0, m_alpha.alphaLinkedListBindGroup);
alphaPass.setBindGroup(1, m_global.cameraBindGroup);
alphaPass.setVertexBuffer(0, m_cubeMesh.vertexBuffer);
alphaPass.draw(DrawCommand{ .vertexCount = 36, .instanceCount = 1 });
alphaPass.end();
}
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
The corresponding fragment shader performs the lock-free insertion.
- It atomically increments the global node counter to claim a slot
- Writes the alpha fragment color and depth into that slot
- Records the previous head pointer in the alpha fragment struct (allowing linked list traversal later)
- Then atomically swaps the head pointer for the current pixel so the new node points to the previous head — forming the linked list one fragment at a time:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 | void main()
{
// Get next free entry in fragments buffers
// We treat 0 as the end of the linked list so we offset every value by 1
uint nodeIdx = atomicAdd(alphaFragments.nextIdx, 1) + 1;
// If we still have room in the fragments buffers
if (nodeIdx < alphaFragments.fragments.length()) {
// Insert new fragment entry
alphaFragments.fragments[nodeIdx].color = adsModel(color);
alphaFragments.fragments[nodeIdx].depth = gl_FragCoord.z;
// Update alphaHeadPointer to nodeIdx for current fragment
uint previousHeadIdx =
imageAtomicExchange(alphaHeadPointer, ivec2(gl_FragCoord.xy), nodeIdx);
// Set next to previousHeadIdx (0 is considered as the ending index)
alphaFragments.fragments[nodeIdx].next = previousHeadIdx;
}
}
|
Filename: compute_oit_transparency/alpha.frag
Compositing Pass
After the alpha pass, barriers ensure all fragment writes to the SSBO and head-pointer image are visible to the compositing fragment shader. A full-screen quad (6 vertices, no vertex buffer) reads the linked list and blends the sorted fragments into the swapchain image:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44 | // Compositing
{
// Wait until fragment Heads pointer image writes have been completed
commandRecorder.textureMemoryBarrier(KDGpu::TextureMemoryBarrierOptions{
.srcStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::FragmentShaderBit),
.srcMask = KDGpu::AccessFlagBit::ShaderWriteBit,
.dstStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::FragmentShaderBit),
.dstMask = KDGpu::AccessFlagBit::ShaderReadBit,
.oldLayout = KDGpu::TextureLayout::General,
.newLayout = KDGpu::TextureLayout::General,
.texture = m_alpha.fragmentHeadsPointer,
.range = {
.aspectMask = KDGpu::TextureAspectFlagBits::ColorBit,
.levelCount = 1,
},
});
// Wait until fragment SSBO list writes have been completed
commandRecorder.bufferMemoryBarrier(KDGpu::BufferMemoryBarrierOptions{
.srcStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::FragmentShaderBit),
.srcMask = KDGpu::AccessFlagBit::ShaderWriteBit,
.dstStages = KDGpu::PipelineStageFlags(KDGpu::PipelineStageFlagBit::FragmentShaderBit),
.dstMask = KDGpu::AccessFlagBit::ShaderReadBit,
.buffer = m_alpha.fragmentLinkedListBuffer,
});
// Render Compositing full screen quad to screen
auto compositingPass = commandRecorder.beginRenderPass(RenderPassCommandRecorderOptions{
.colorAttachments = {
{
.view = m_swapchainViews.at(m_currentSwapchainImageIndex),
.clearValue = { 0.3f, 0.3f, 0.3f, 1.0f },
.initialLayout = TextureLayout::Undefined,
.finalLayout = TextureLayout::PresentSrc,
},
},
.depthStencilAttachment = {
.view = m_depthTextureView,
},
});
compositingPass.setPipeline(m_compositing.graphicsPipeline);
compositingPass.setBindGroup(0, m_alpha.alphaLinkedListBindGroup);
compositingPass.draw(DrawCommand{ .vertexCount = 6 });
compositingPass.end();
}
|
Filename: compute_oit_transparency/compute_oit_transparency.cpp
For each fragment of the full screen quad, the compositing fragment shader traverses the per-pixel linked list.
- It does so by first retrieving the head pointer for the given fragment coordinges in the head pointer image.
- Then since each Alpha Fragment stores a
next pointers, it collects up to 32 fragment indices into a local array.
- Next it runs an insertion sort by depth (front-to-back), then blends the sorted colors using
mix() with each fragment's own alpha:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 | void main()
{
// Retrieve all Alpha Fragments
uint alphaHeadPtr = imageLoad(alphaHeadPointerTexture, ivec2(gl_FragCoord.xy)).r;
const uint MAX_FRAGMENT_COUNT = 32;
uint alphaFragmentIndices[MAX_FRAGMENT_COUNT];
uint alphaFragmentIndexCount = 0;
while (alphaHeadPtr > 0 && alphaFragmentIndexCount < MAX_FRAGMENT_COUNT) {
alphaFragmentIndices[alphaFragmentIndexCount] = alphaHeadPtr;
alphaHeadPtr = alphaFragments.fragments[alphaHeadPtr].next;
++alphaFragmentIndexCount;
}
// Sort Alpha Fragments by Depth (biggest depth first)
if (alphaFragmentIndexCount > 1) {
for (uint i = 0; i < alphaFragmentIndexCount - 1; i++) {
for (uint j = 0; j < alphaFragmentIndexCount - i - 1; j++) {
if (alphaDepth(alphaFragmentIndices[j]) > alphaDepth(alphaFragmentIndices[j + 1])) {
swap(alphaFragmentIndices[j], alphaFragmentIndices[j + 1]);
}
}
}
}
vec4 blendedColor = vec4(0.0);
for (uint i = 0; i < alphaFragmentIndexCount; i++) {
vec4 alphaFragColor = alphaColor(alphaFragmentIndices[i]);
blendedColor = mix(blendedColor, alphaFragColor, alphaFragColor.a);
}
fragColor = blendedColor;
}
|
Filename: compute_oit_transparency/compositing.frag
Vulkan Requirements
- Vulkan Version: 1.0+ (compute shaders are core)
- Extensions: None required (atomic operations are core)
- Features: Compute shader support, atomic operations on storage buffers, image atomics
See VkShaderStageFlagBits - Compute Shader and Atomic Operations
Further Reading
Updated on 2026-07-16 at 00:01:15 +0000